Function: the atomic unit of code¶
The First Nine Guide. Блок 1
Функции - важная штука внутри каждого приложения. Когда в сервис приходят запросы, они вызывают под собой функции. Какие-то работают медленно, какие-то быстро. Чтобы лучше понимать в чем их разница и какие они вообще бывают, я классифицирую их по нескольким признакам:
- По сложности алгоритма внутри функции.
- По типу ресурса, который потребляет функция.
- По потокобезопасности.
Погнали по порядку.
Алгоритмическая сложность¶
Функция - это базовый кирпич производительности. Первая и самая грубая оценка ее поведения - это Big-O (O-большое).
Перед тем как вы будете закатывать глаза, скажу: не буду мучать математикой, тут все предельно просто. Чтобы не потеряться при анализе медленного кода, достаточно:
- отличать O(1) от O(n^2)
- понимать, что O(n log n) - граница, за ней только вечная боль
- замечать, когда алгоритм внезапно становится O(n!)
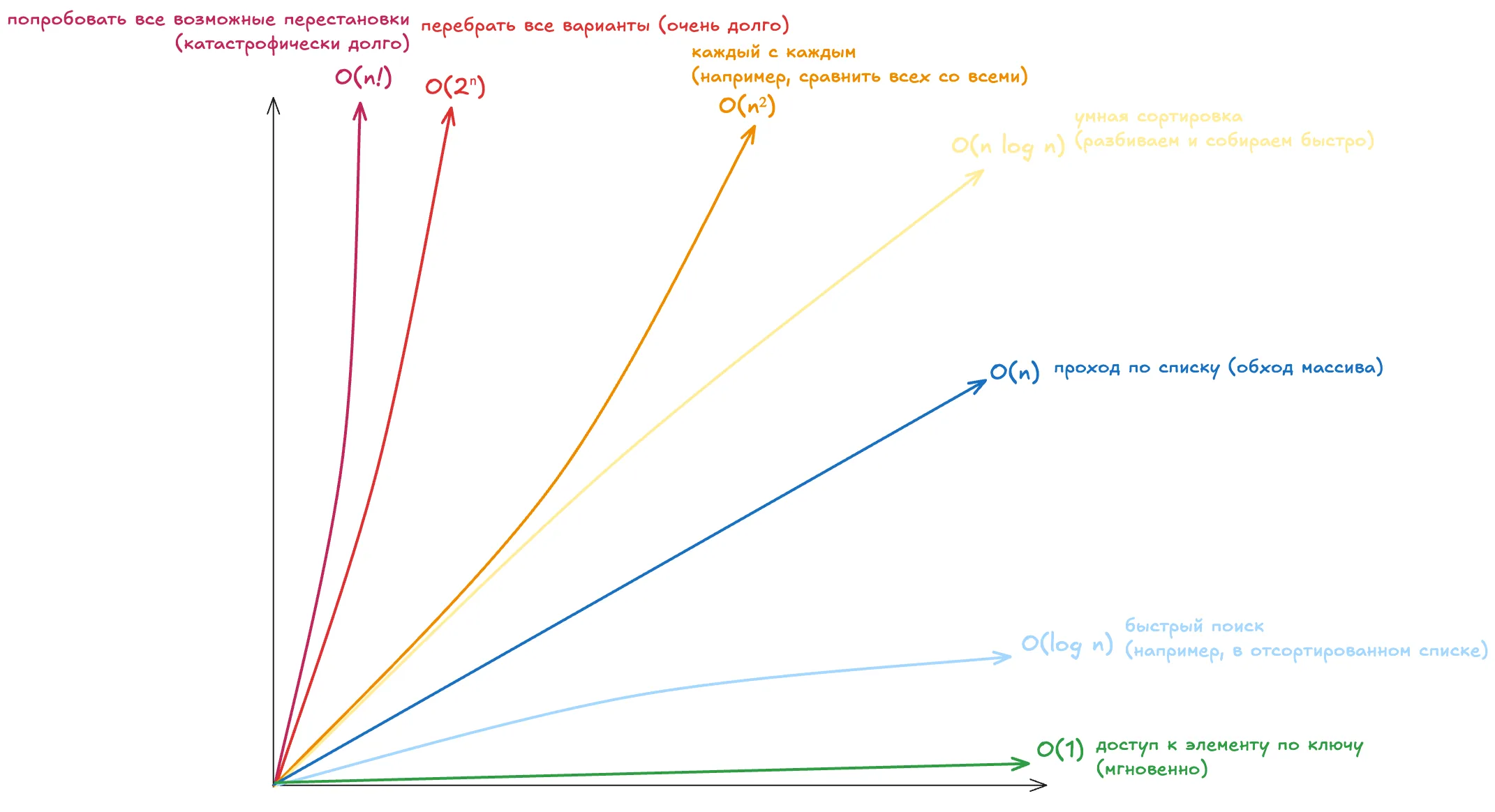
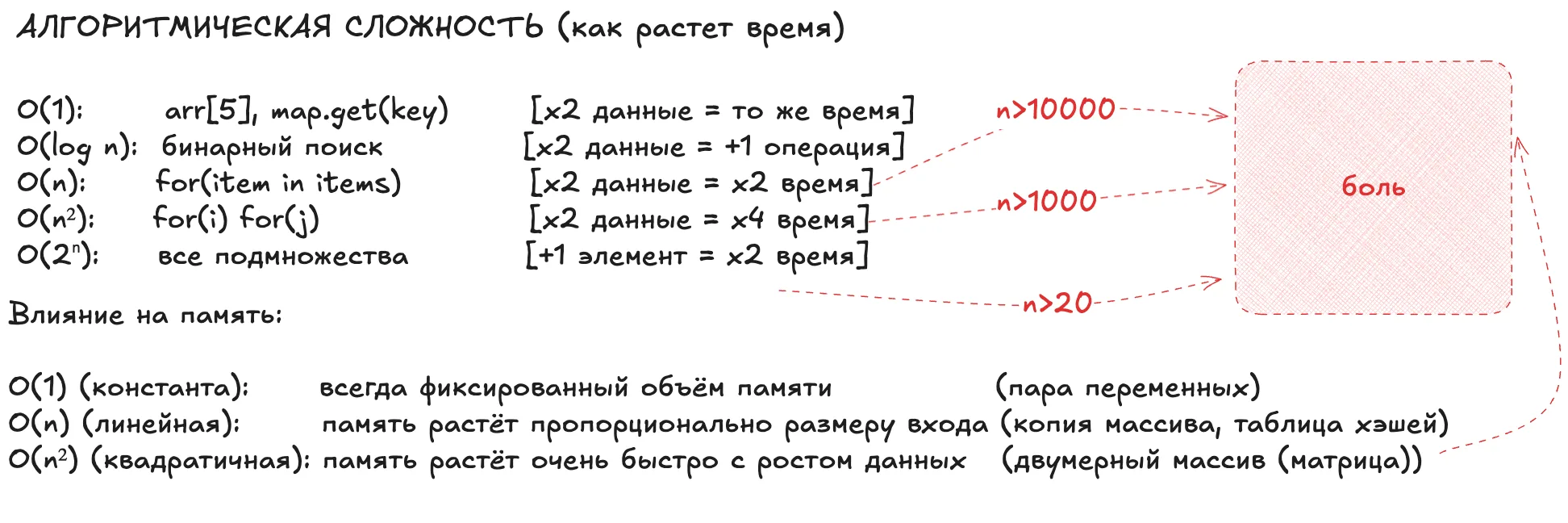
Выше желтой линии начинает деградировать производительность при росте объема данных.
Вот примеры и пороги для n (для O(n!) реальных примеров придумать не смог):
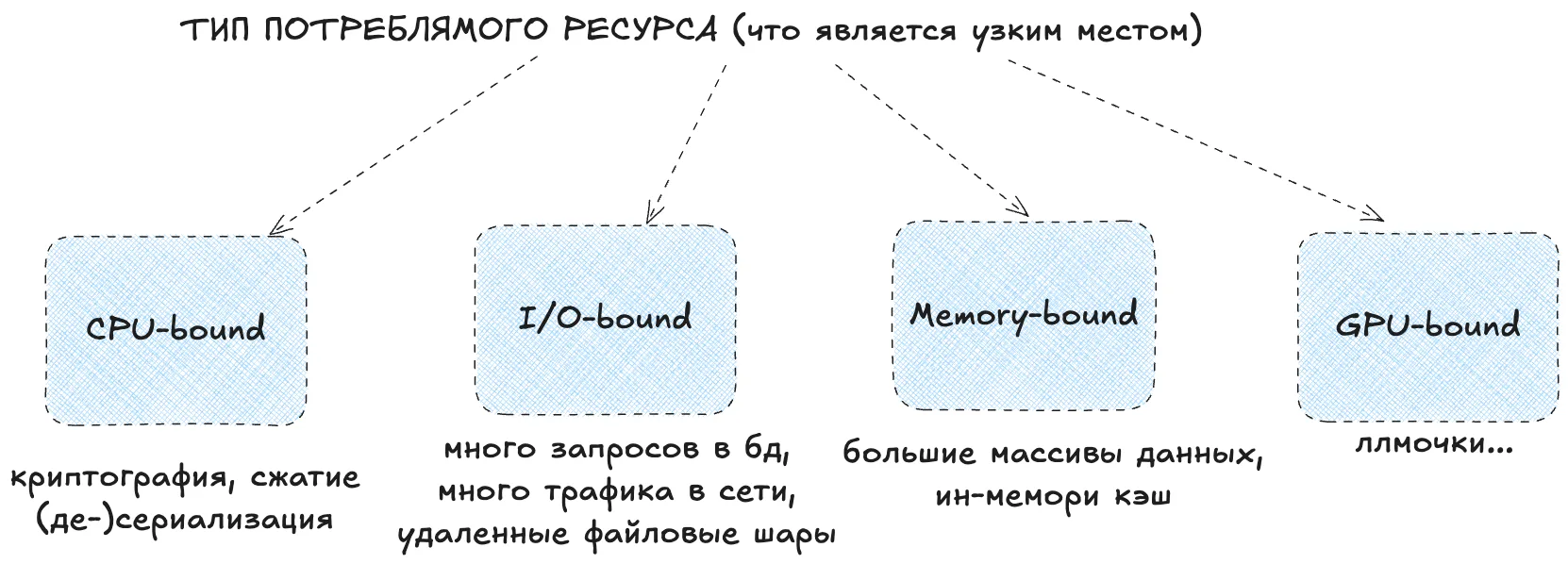
Типы потребляемых ресурсов¶
Скорость выполнения - это не все, мы же про перформанс.
Некоторые функции ждут диск, сеть или кэш, другие - кушают CPU.
Нам важно классифицировать функцию (желательно на этапе ее написания):
- IO-bound - ждет сеть, диск, БД
- CPU-bound - парсит, считает
- Memory-bound - тащит данные из RAM, но не нагружает CPU
- GPU-bound - понятно, кушает GPU
Это важно, чтобы понимать, где может быть зарыт ботлнек: в ядре, памяти, сокете или в алгоритме.
Потокобезопасность¶
Если код запускается параллельно - а он почти всегда запускается параллельно - важно ответить на вопросы:
- а мы не испортим ли общие данные?
- а мы не заблокируем ли соседей?
Разделяют 3 категории функций:
- Thread-safe - можно вызывать из любого потока
- Thread-unsafe - может все поломать (знайте их в лицо)
- Conditionally-safe - безопасен только при соблюдении условий
Потокобезопасные (Thread-safe):
- Работают с неизменяемыми (immutable) данными.
- Не имеют общего изменяемого состояния.
- Доступ к общим данным синхронизирован (через локи).
- Используют только атомарные операции.
Потоконебезопасные (Thread-unsafe):
- Изменяют глобальное состояние.
- Используют статичные изменяемые переменные.
- Выполняют неатомарные операции "чтение-модификация-запись".
- Примеры: strtok() в C, SimpleDateFormat в Java.
Условно-безопасные:
- Безопасны при использовании внешней синхронизации.
- Операции только для чтения над общими данными.
Call overhead¶
Каждый вызывающий вызов, любой функции, создает отдельный участок памяти под себя - он называется stack frame.
Каждый новый вызов создает новый фрейм наверху стека. Когда функция выполнена, кадр удаляется. Даже int sum(int a, int b) создает 16-64 байта накладных расходов.
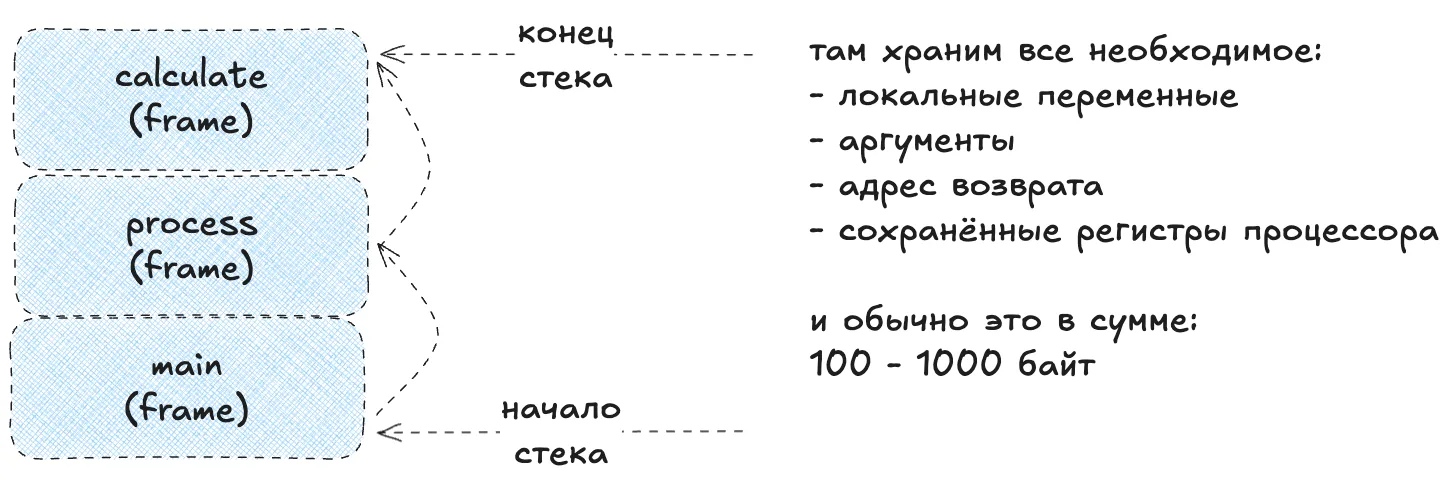
Зачем это вообще знать?
Просто:
- Сколько времени требуется на создание stack frame? 10-50 CPU циклов (очень быстро, но вот в цикле может быть больно).
Чем глубже закопана функция в коде через цепочку вызовов, тем дороже ее вызывать (привет, stack overflow). Лямбды/анонимные функции еще дороже.
Грязный хак: inline-функция. Она не тащит создание stack frame, но try/catch/finally ломают inlining.
Типичные ловушки (заворачиваем с собой)¶
Циклы:
- Конкатенация строк в цикле (str += char часто дает O(n^2)).
- Вложенные циклы по большим коллекциям (особенно не конечным коллекциям).
Риск переполнения стека (Stack Overflow):
- Каждый вызов функции создает фрейм на стеке (~100-1000 байт).
- Слишком глубокая рекурсия исчерпает стек (обычно ~1 МБ по умолчанию).
Hybrid-bound функции, смешивание типов:
- Blocking I/O в CPU функции сложно дебажить и скейлить, лучше избегать.
В следующем выпуске - разбор runtime моделей.
Подписывайся на канал @r9yo11yp9e - будем искать девятки вместе.