Ideal application deployment¶
The First Nine Guide. Блок 4

Итак, наконец-то - мы написали идеальное веб-приложение:
- В нем проработана и снижена комплексность каждого метода и функции, как это мы разбирали в блоке 1.
- Мы выбрали лучший рантайм под задачу, опираясь на модели из блока 2.
- При написании кода мы понимали внутреннюю архитектуру, от этого приложение получилось устойчивым.
И подошли вплотную к моменту, когда нам надо запускать его в проде. Ну и конечно в контейнере. Разберемся, что может пойти не так. Попутно оценим языки и фреймворки за то, насколько они позволяют пройти этот путь без ловушек и боли.
Как будем разбираться? Всем сделаем схему в ключевых вариантах упаковки в контейнер.
В каждой схеме три контейнера сверху вниз:
1) Наивный - запускаем "как есть", без тюнинга: проявляются типовые проблемы.
2) Подкрученный - снимаем CPU limits (quota=0) и фиксируем базовые ресурсы: убираем CFS throttling и непредсказуемость.
3) Идеальный - согласованные ресурсы (requests/параллелизм) и лимиты памяти.
Справа от контейнеров подсвечиваю работу с тредами, параллелизм и их маппинг на тяжелые потоки ОС.
Почему рекомендую снимать CPU limits?
- Максимально упрощенно: ядро начинает искусственно притормаживать процесс (CFS throttling). Время ответа скачет, при коротких пиках не хватает CPU.
- Что оставляем: cpu.requests - целевая доля CPU для планировщика Kubernetes, и обязательно memory.limits + memory.requests.
(в целом на это будет отдельный пост в канале, но ради холивара - залетайте в комменты)
Когда лимиты нужно оставить?
Когда у вас неконтролируемое потребление CPU, например если контейнер хочет съесть все ядра ноды. Лимиты оправданы при недоверенном коде или шаренном кластере. Подход без cpu.limits требует завышать cpu.requests относительно реального потребления, за этим надо следить. Тестируйте перед тем как снимать лимиты.
Java Virtual Machine 11+¶
Ранее я писал пост про то как настраивать JVM и не взорваться в проде. Коротко продублирую, чтобы статья была полной.
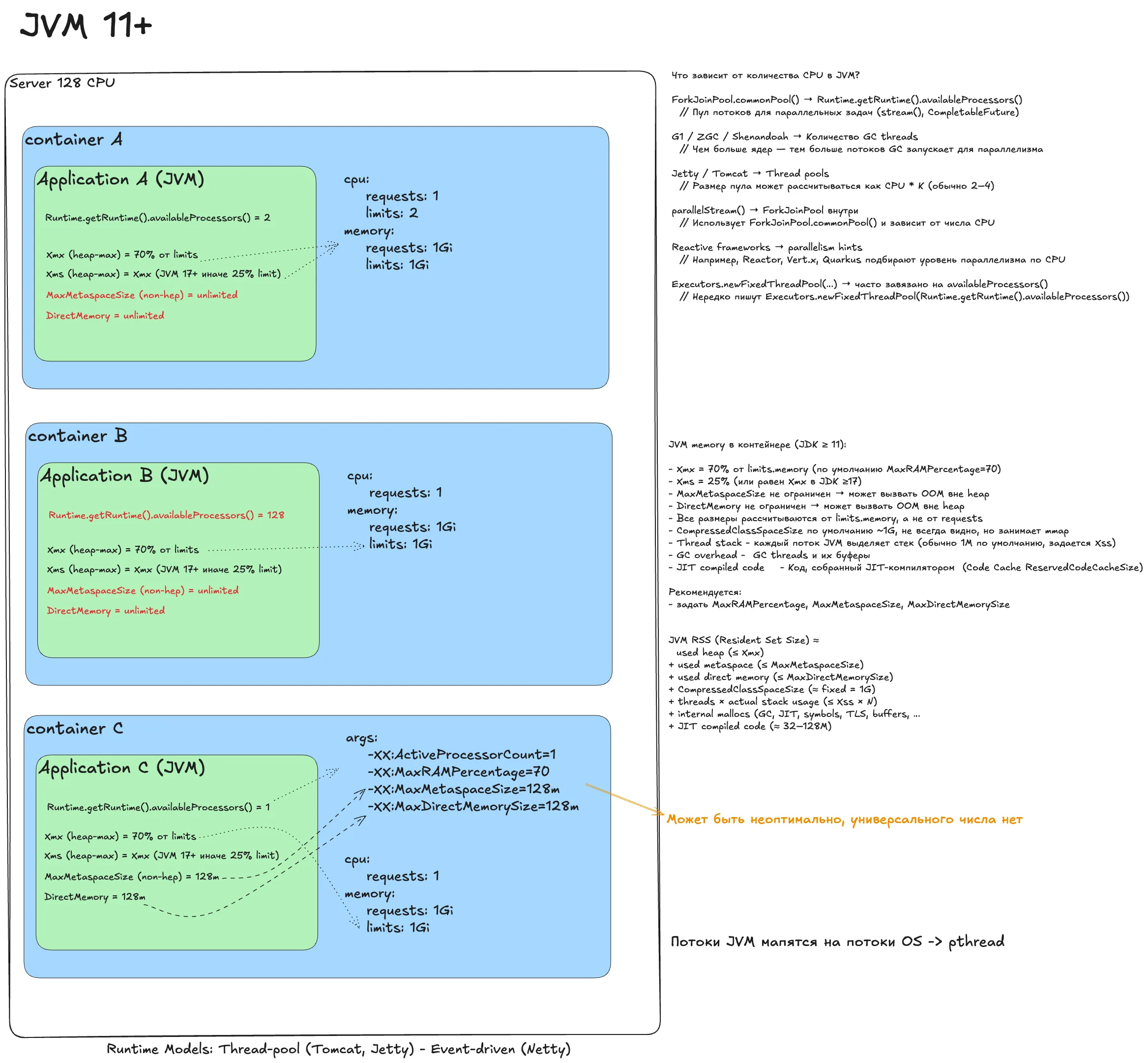
Наивный деплой
JVM видит лимит в 2 CPU и настраивает параллелизм под него: GC, ForkJoinPool и пулы веб-серверов (Tomcat). Проблема: троттлинг на старте, скачки латенси, off-heap утечки.
Снимаем троттлинг
В контейнере B убираем лимиты. Ловушка: JVM, не видя лимита, смотрит на всю ноду и решает, что ей доступны все 128 ядер. availableProcessors() возвращает 128, рантайм создает огромное число потоков. Итог: контекстные переключения, борьба за ресурсы, деградация. Приложение пытается использовать 128 ядер, имея гарантию только на одно.
Идеальный деплой
Убираем лимиты, но даем JVM понять, сколько ресурсов реально гарантировано. Выставляем -XX:ActiveProcessorCount=1 (равно requests). JVM корректно настраивает параллелизм, избегает троттлинга и не взрывает количество потоков. Дополнительно настраиваем память (-XX:MaxRAMPercentage, -XX:MaxMetaspaceSize), чтобы избежать OOM Killer.
Java Virtual Machine 21+ (Virtual Threads)¶
Добавим про JVM с virtual threads.
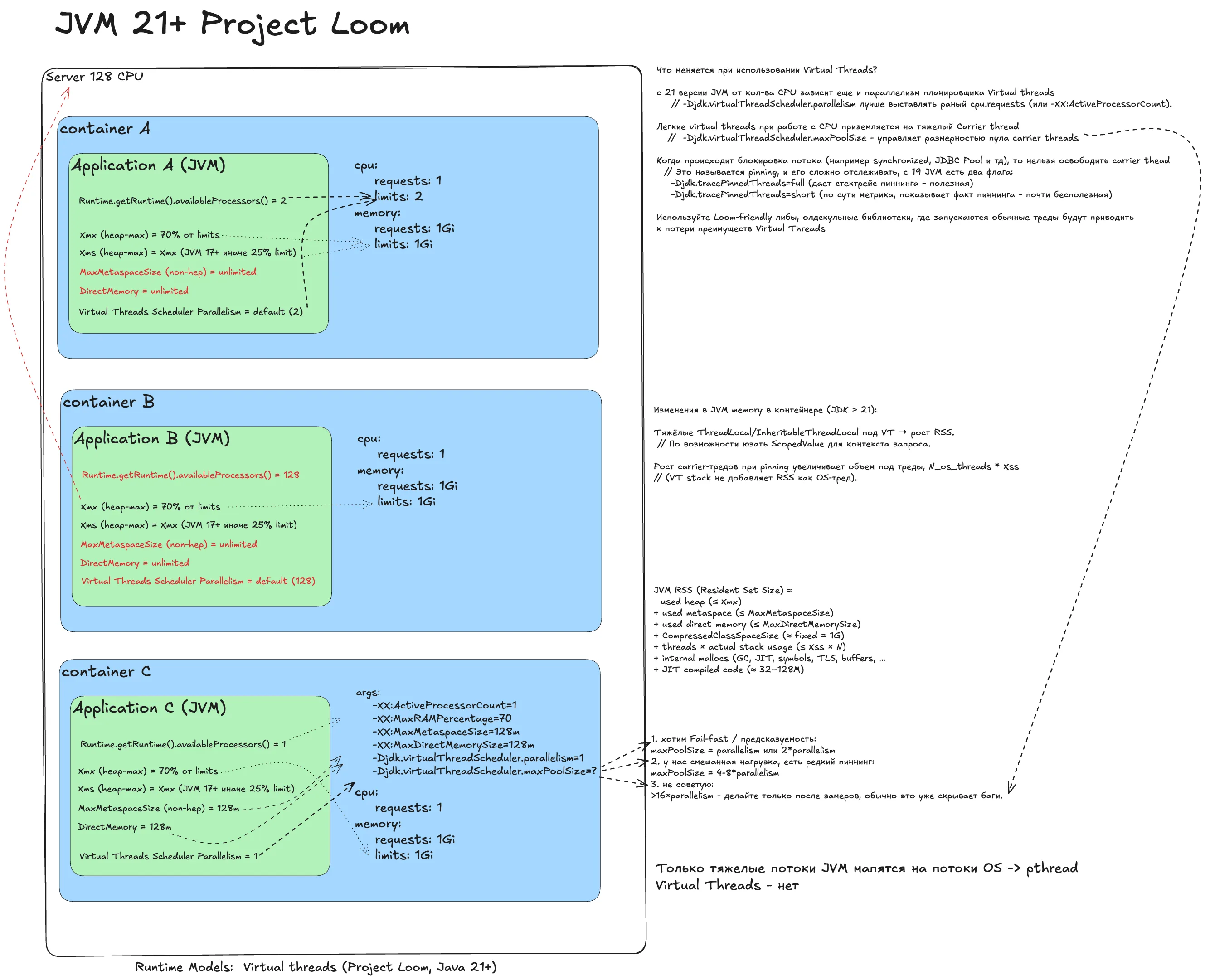
Наивный деплой
Все как в JVM 11+: реквесты/лимиты, троттлинг. Плюс планировщик virtual threads тоже ориентируется на лимиты.
Снимаем троттлинг
Убираем лимиты - тяжелых тредов планировщика становится слишком много, от этого копятся виртуальные потоки.
Идеальный деплой
Убираем лимиты и делаем как в JVM 11+, но добавляем второй флаг:
- -XX:ActiveProcessorCount=1 - управление параллелизмом GC и ForkJoinPool.
- -Djdk.virtualThreadScheduler.parallelism=1 - настройка пула тяжелых потоков для виртуальных тредов.
Так мы согласовываем параллелизм рантайма с выделенными ресурсами и получаем предсказуемое поведение.
Golang 1.10+¶
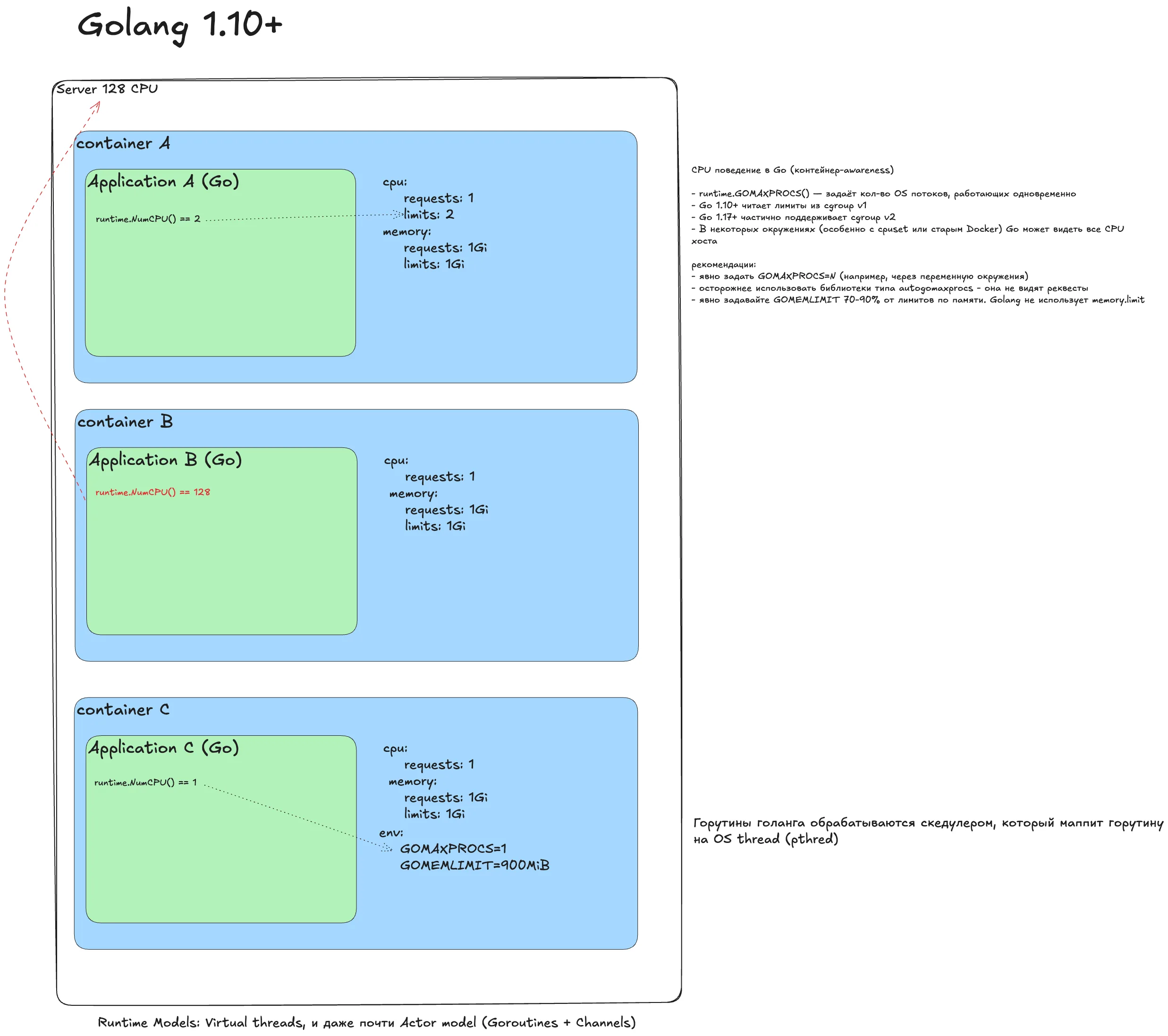
Наивный деплой
Запускаем с реквестами и лимитами. Рантайм Go видит лимиты, runtime.NumCPU() вернет 2. Проблемы: CPU throttling и GC не знает границы контейнера - возможен OOMKill.
Снимаем троттлинг
Убираем лимиты. Ловушка: рантайм Go видит всю машину и runtime.NumCPU() возвращает 128. Планировщик создает 128 системных потоков. Итог - деградация.
Идеальный деплой
Явно указываем, сколько ядер использовать: GOMAXPROCS=1 (из requests). GOMEMLIMIT лучше ставить в 70-90% от memory limit, так как Go игнорирует memory.limit. Для автоматизации - automemlimit. Рантайм понимает границы контейнера и предсказуемо масштабируется.
Node.js 18+/20+¶
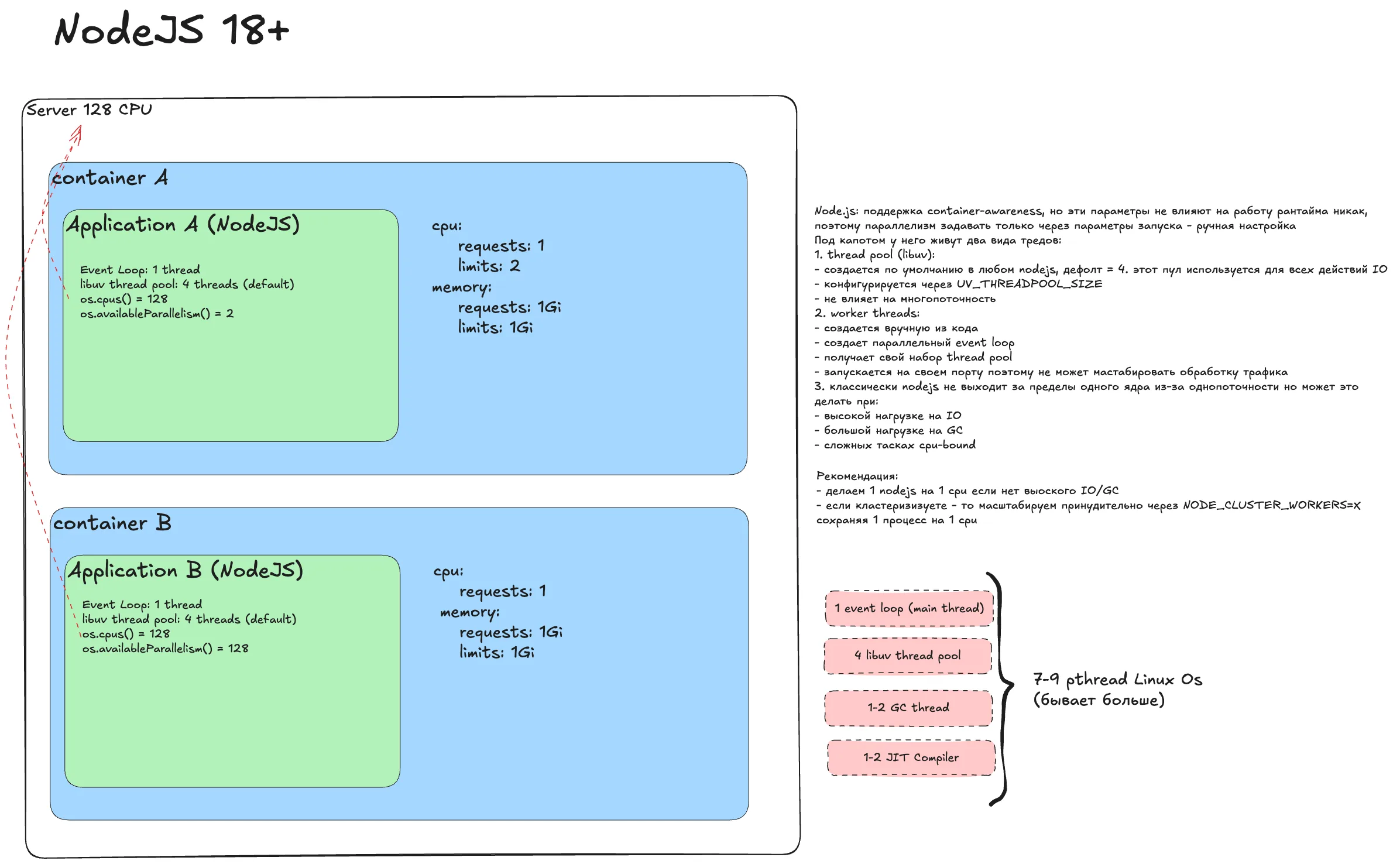
Наивный деплой
Реквесты 1, лимиты 2. Основной поток Node.js однопоточный, libuv pool по умолчанию 4. Проблем минимум, кроме CPU throttling при CPU-bound задачах.
Снимаем троттлинг
Тут почти ничего не случится. Node.js не взорвется и не попытается использовать все ядра. Но и эффективного параллелизма не появится.
Идеальный деплой
Правильный деплой для Node.js - масштабирование. Рекомендую держать количество процессов равным requests. Это дает прозрачность и утилизацию.
Python 3.8+ (Gunicorn / Uvicorn)¶
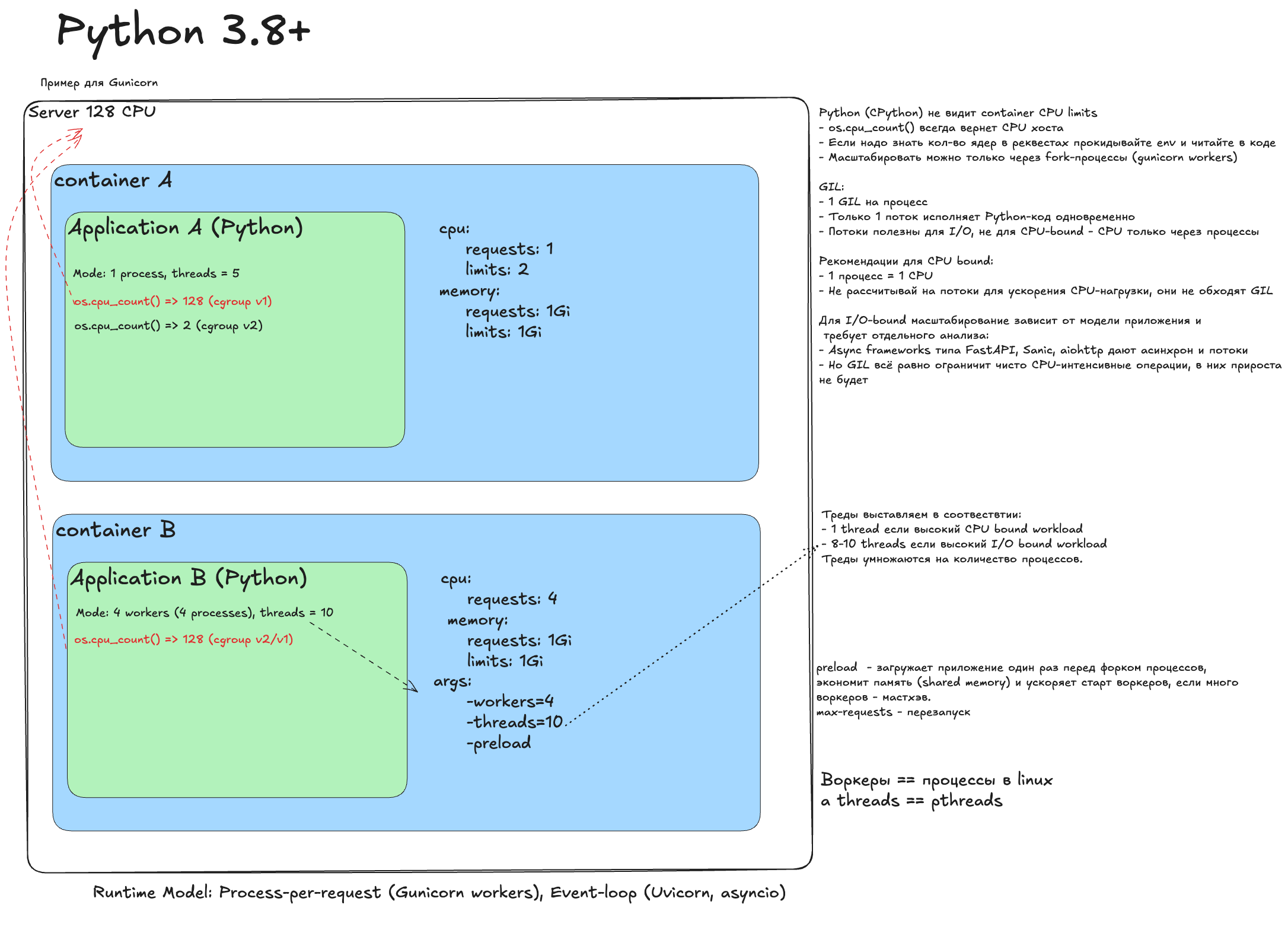
Наивный деплой
В сердце Python живет GIL, код выполняется в одном потоке. Можно уходить в псевдопараллелизм на уровне процессов. Наивный деплой обычно ок, но троттлинг возможен.
Снимаем троттлинг
Убираем лимиты. Ловушка: C-библиотеки (NumPy, Pandas, OpenCV) могут увидеть 128 ядер и распараллелить вычисления. Результат - борьба за ресурсы.
Идеальный деплой
- Gunicorn processes = requests.
- Для взрывоопасных библиотек: OPENBLAS_NUM_THREADS=1 и аналоги.
- Для долгоживущих воркеров: max-requests(+jitter), preload.
Ruby 3+¶
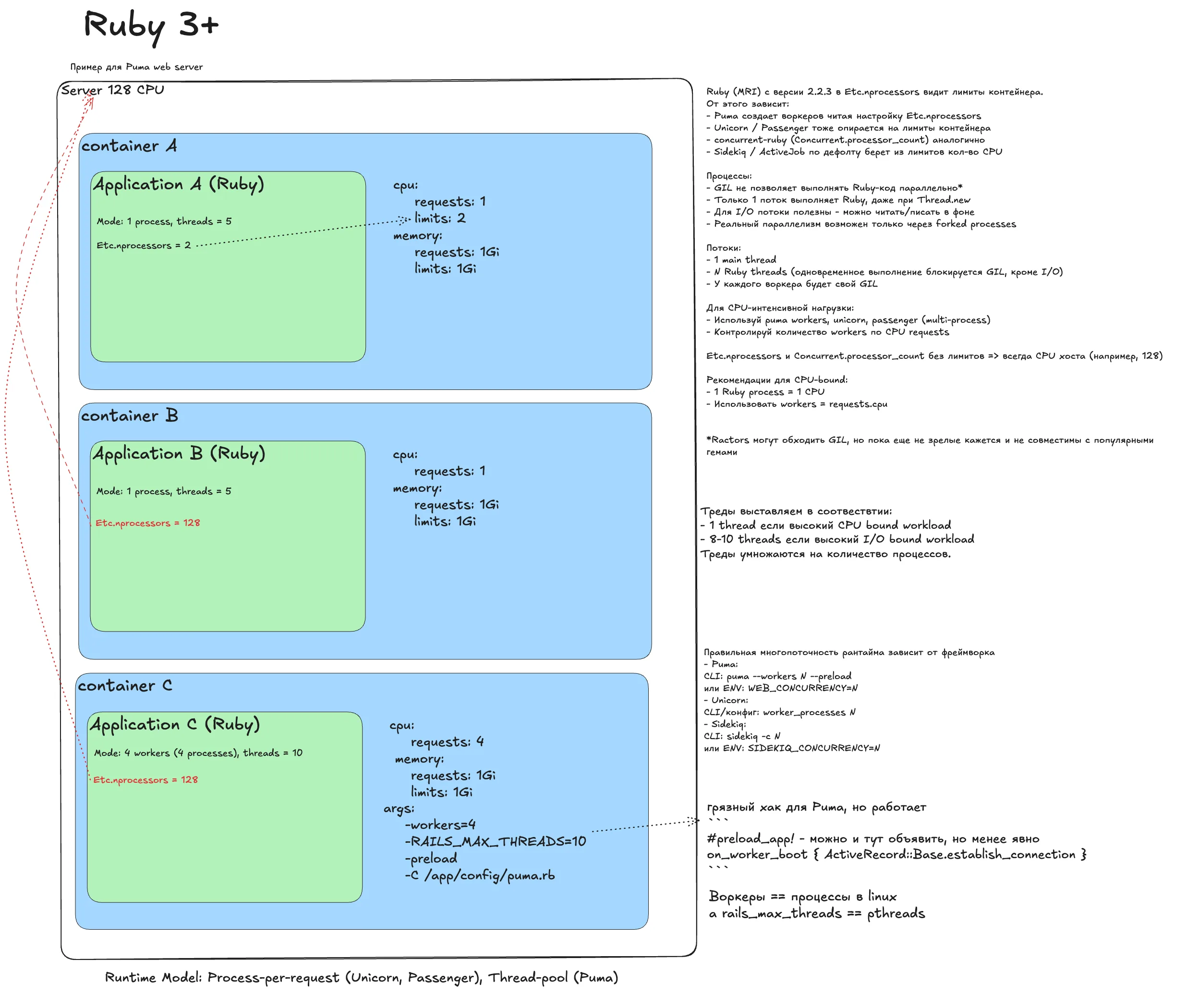
Наивный деплой
Однопоточный рантайм MRI. Проблемы троттлинга те же, но в целом наивный деплой чаще всего терпим.
Снимаем троттлинг
Убираем лимиты. Ловушка: Puma использует Etc.nprocessors. Без лимитов он увидит все ядра и попытается создать слишком много процессов или потоков.
Идеальный деплой
Настраиваем явно:
- WEB_CONCURRENCY=1 (по requests) - количество процессов-воркеров.
- RAILS_MAX_THREADS=5 - размер пула потоков внутри воркера (зависит от нагрузки).
- Для Unicorn и Sidekiq аналогично задаем воркеры/конкурентность явно.
PHP-FPM 7.4+¶
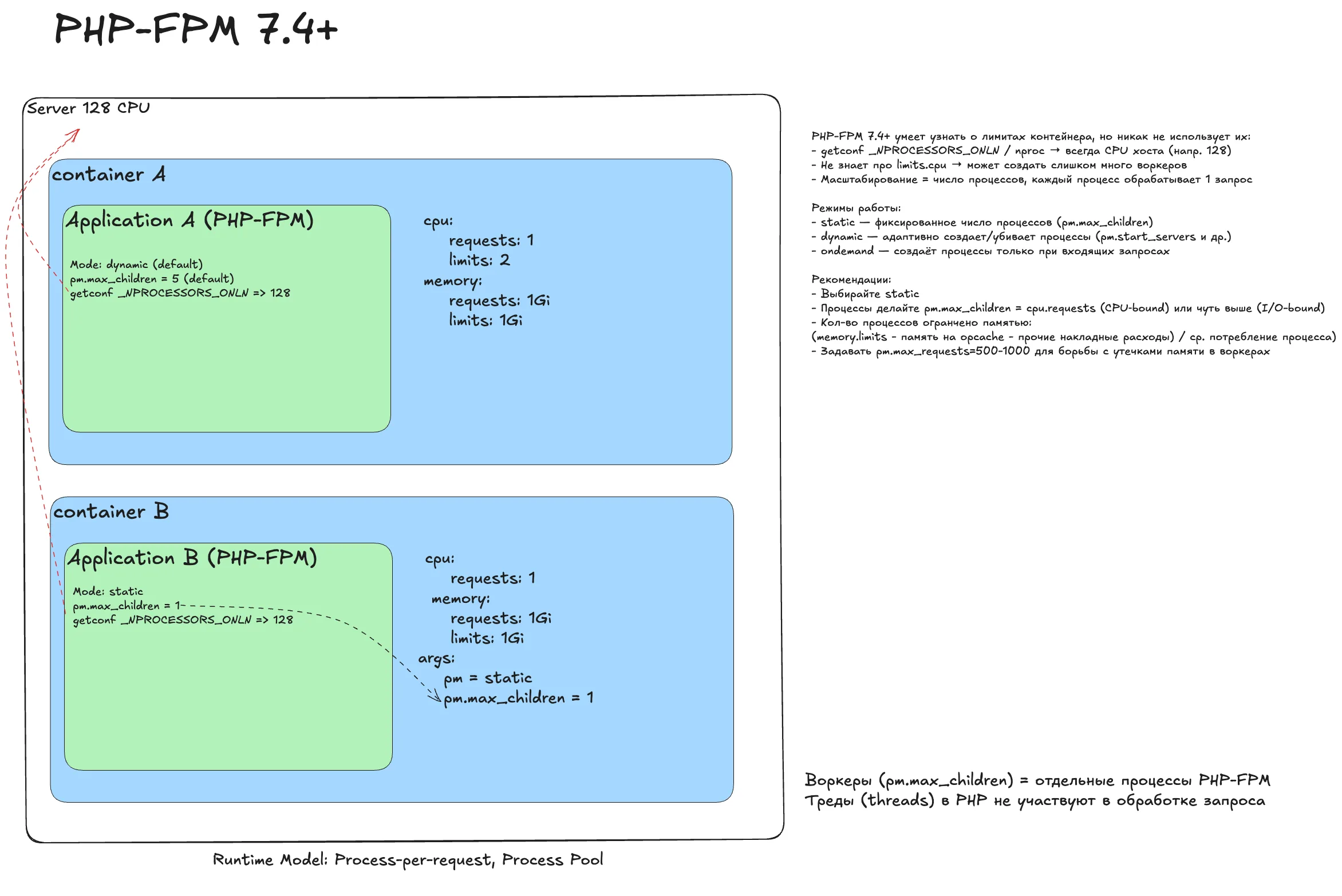
Наивный деплой
PHP-FPM работает в режиме dynamic (по умолчанию), создавая и удаляя процессы по мере необходимости (process-per-request). Прожорливое приложение почти всегда упирается в лимиты и страдает. Динамический режим (pm=dynamic) может давать скачки памяти и непредсказуемость.
Снимаем троттлинг
Лимиты убираем. PHP-FPM не взрывается сам по себе. Ловушка: если библиотека пытается определить CPU через getconf _NPROCESSORS_ONLN, она увидит все 128 ядер.
Идеальный деплой
- Режим управления процессами: pm = static.
- Количество процессов: pm.max_children = 1 (равно cpu.requests).
Такое распределение дает стабильное и предсказуемое поведение. Из-за отсутствия постоянного рантайма PHP-FPM сложнее профилировать, но это решают Roadrunner и FrankenPHP.
.NET 6+¶
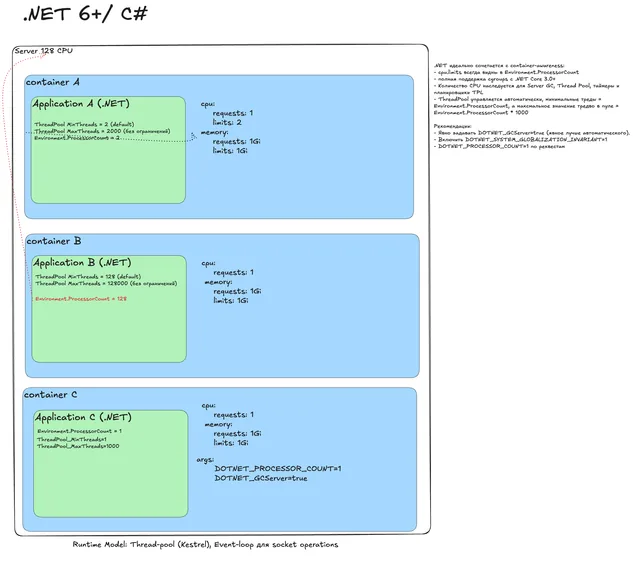
Наивный деплой
Рантайм .NET хорошо container-aware: видит лимит в 2 CPU, настраивает ThreadPool и GC. Но троттлинг все равно возможен.
Снимаем троттлинг
Убираем лимиты. Ловушка: рантайм видит все ядра ноды и раздувает ThreadPool. Приложение получает гарантию 1 CPU, но планирует на 128.
Идеальный деплой
Настраиваем рантайм под requests:
- DOTNET_PROCESSOR_COUNT=1 - наследуется во все пулы.
- DOTNET_GCServer=true - серверный GC для предсказуемости (иногда не нужен, но уменьшает неопределенность).
Ранее я пытался приводить сводную таблицу с субъективной оценкой рантаймов. Сейчас считаю, что объективно ее провести нельзя. Поэтому оставил эту затею и сфокусировался на ловушках и рекомендациях.
Статью буду дополнять, чтобы она служила актуальной шпаргалкой. Буду фиксить найденные узкие места и неточности - велкам в комменты.
В следующем выпуске мы наконец-то поймем кто такой "тяжелый поток" и как с ним поладить.
В предыдущей серии - разбирались с тем, как устроен веб-сервер внутри.
Подписывайся на канал @r9yo11yp9e - будем искать девятки вместе.